The rapid development of pretrained foundation models has enabled more general image segmentation.
Multimodal Large Language Models (MLLMs) have been widely explored for image segmentation with complex
queries that require high-level reasoning. Despite promising progress, existing methods are often
constrained by limited training data and the gap between MLLMs and mask generation modules. To better
transfer MLLMs' perception and reasoning ability to complex reasoning-based segmentation tasks, we propose
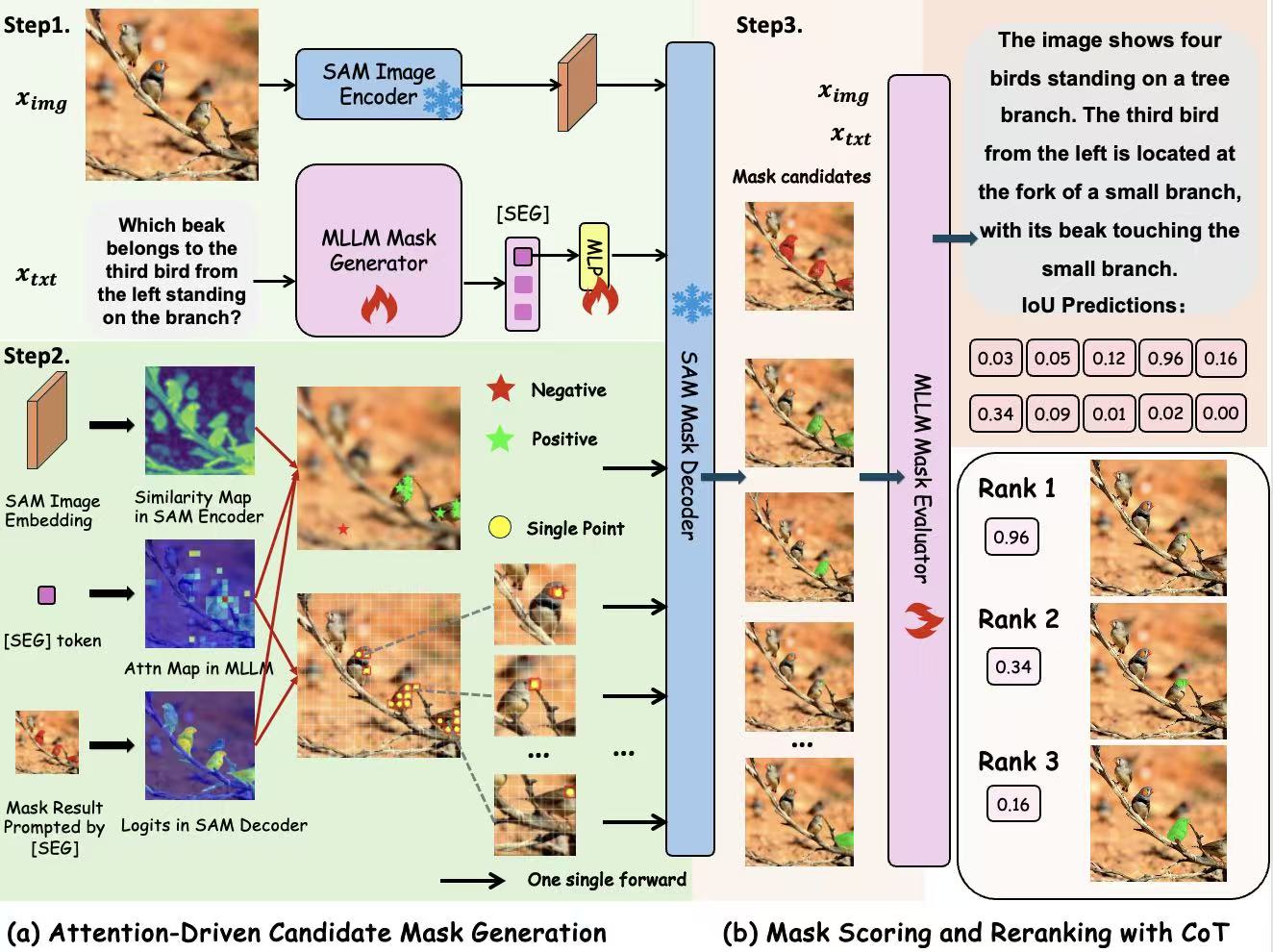
a two-stage framework, Rea2Seg, for mask generation and selection.
Specifically, the framework first identifies potential regions as candidate masks based on the attention
maps of a segmentation MLLM. It then employs an MLLM to reason over the question and candidate masks and
assign a score to each mask. The final segmentation result is obtained by reranking the candidates and
selecting the highest-scoring mask, reformulating image segmentation as candidate discovery followed by
discriminative mask selection.
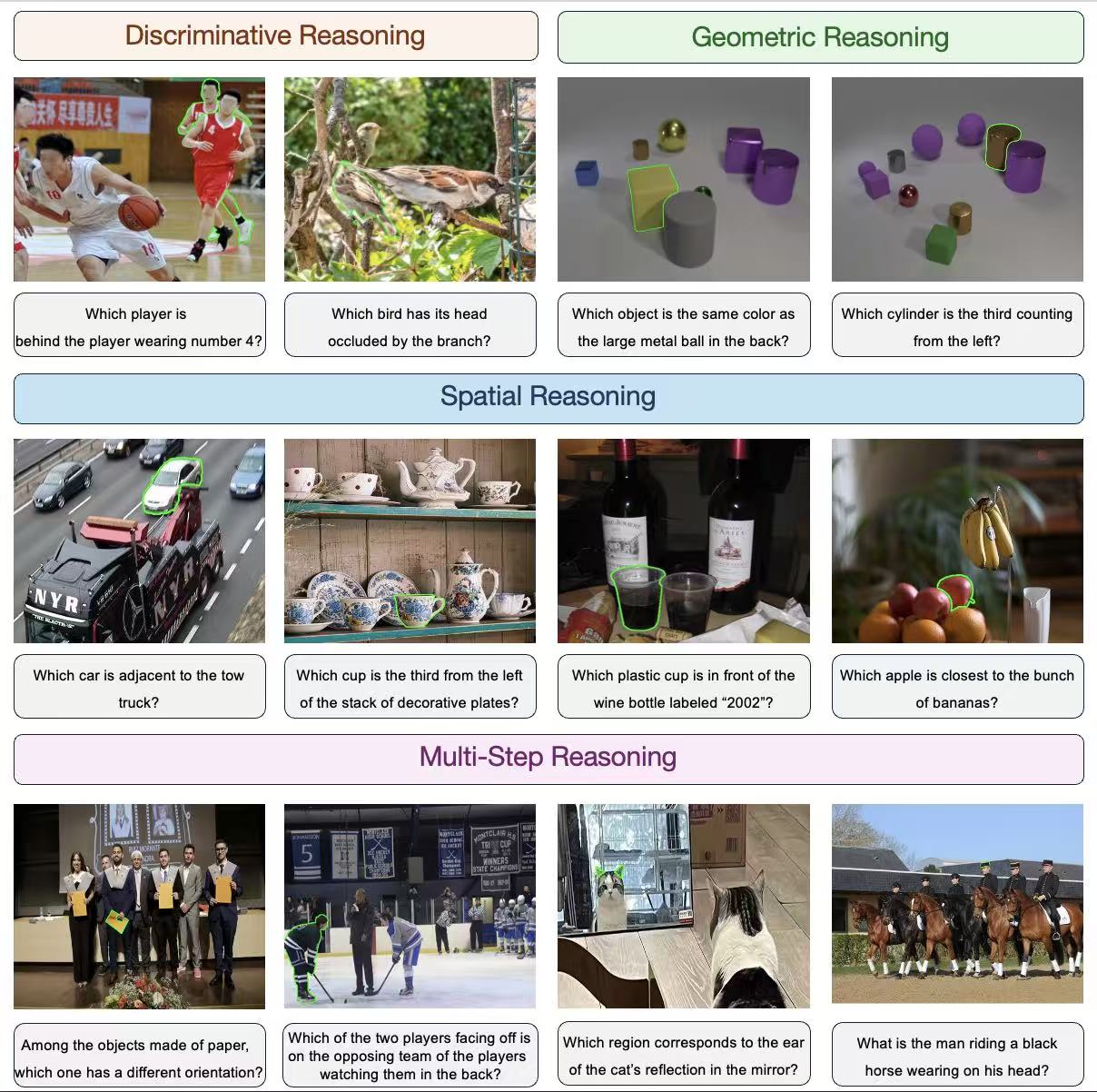
We also observe that a large portion of questions in existing benchmarks focus on commonsense reasoning
and do not fully require joint visual observation and reasoning. To address this issue, we introduce
a new benchmark, ReasonSeg-SGDR, which comprehensively evaluates a model's perception, grounding, and reasoning
abilities across multiple dimensions, including discriminative recognition, spatial reasoning, geometric
reasoning, and multi-step reasoning, with fine-grained mask annotations.
In addition, we collect a 16K-sample training dataset, Rea2Seg-16K, for reasoning segmentation with detailed
chain-of-thought annotations. We further convert this dataset into a mask-scoring dataset to enhance
MLLMs' ability to jointly interpret multimodal queries and candidate masks, and to assign scores through
reasoning.
Experimental results on ReasonSeg-SGDR and ReasonSeg demonstrate the effectiveness of the unified mask generation and selection framework.